How AI Systems Will Talk: APIs, MCP, and A2A meet Agent Languages
AI-to-AI communication is harder to achieve than it looks. This post looks at the intersection of Web APIs, MCP, A2A, and previous generations of Agent Communication. Drawing practical lessons for today's system communications.

Machines talk to each other constantly. That machine-to-machine traffic is what makes the modern internet work.
Every click and API call triggers a cascade of machine messages. Even email is chunked into packets, transmitted, reassembled, queued for delivery, and finally read by the recipient.
Modern web apps call external APIs for storage, payments, weather, and more. APIs also run fully machine-only workflows. Trading bots ingest live market data. Backup systems trigger themselves. Distributed computing projects like SETI@Home process images at scale.
But what happens when we introduce AI into this world?
Model Context Protocol (MCP) and Agent-to-Agent (A2A) are the best-known new approaches for how AI systems might talk to one another. As with much technology, this isn't the first attempt to solve this problem.
In this post, we look at:
- How MCP and A2A compare to REST-style Web APIs
- Syntax vs semantics and why this distinction is crucial
- What Agent Languages (like FIPA) from the late 90s and early 2000s can teach us
- Some practical lessons for building AI-to-AI communication
Lastly, before kicking off, I’ve been meaning to write about the intersection of MCP and a new wave of “AI to AI” communication protocols for a while. The opportunity was finally unlocked by the kind invitation to speak at the recent APIDays “No AI without APIs” conference in London.
Thank you so much to the APIDays crew. I highly recommend the events: the next event is in Paris in December!
You can get a more visual version of some of the content in this post from the presentation slides from the event, which you can find here:
The Video of the talk is now also available on YouTube:
On with the blog post....
What MCP and A2A are trying to do
If you'd like a deeper primer on MCP vs regular web APIs, I highly recommend Kevin Swiber’s extensive post to get started. For the purposes of this discussion, we'll keep the introduction high-level. Starting with definitions:
- The Model Context Protocol (MCP) was introduced by Anthropic in 2024. The purpose of the protocol is to make it easier for an LLM to “call” other computational processes to get some sort of a result. This is thought of as “tool calling”. Example tools could be file systems, data providers, storage systems, search, and many other services. In MCP, developers can register an MCP server with an LLM, and the endpoint can provide one or more tools. Each tool, in its simplest form, is specified by a JSON template that defines the input structure and another that defines the form of the output. Communication is carried out using JSON-RPC. This provides a bidirectional, stateful communication channel. Once an MCP server is registered, the LLM can discover tools, activate them, and bring results back into its working context. Thus, an LLM can send a query to a flight search tool, receive a list of relevant flights, bring this into context, and then select a flight to book.
- The Agent-to-Agent (A2A) protocol was first defined by Google and now has a wide array of supporters. Many of the details are similar to MCP. The difference is that A2A is meant for peer-to-peer interaction between intelligent systems, not just ‘LLM calls tool’. This changes the focus of the protocol to interchange of human language messages (though JSON and other formats can be used) and a greater emphasis on standardizing the descriptions of what individual agents are capable of. In terms of implementation, A2A shares many of MCP's fundamentals, using JSON and JSON-RPC, but also allowing for other encodings.
There are also a number of other emerging protocols with similar aims to A2A, but I’ll refer to A2A here specifically as a concrete instantiation of these. Lastly, a short primer on RESTful APIs:
- Most modern Web applications use JSON-based REST APIs for communication. The primary standard for specifying these APIs is the OpenAPI specification (see here for the new v3.2.0 release). REST APIs are client-server interactions with tightly specified inputs and outputs. Typically, having an API specification means one party can implement the server-side logic to carry out the actions the API promises. Many parties can then implement clients that call the API to bring about those effects. REST APIs rely on the HTTP protocol semantics to set the high-level meaning of a particular call (e.g., a “GET” request from a client is a request for a resource from the server).
There are also many other Web API approaches (e.g., GraphQL and AsyncAPI). In this discussion, they could easily be substituted for REST APIs since the principles in terms of syntax and semantics are very similar. (Each has its own syntax and semantics that are tied to a small number of data exchange actions.)
The distinction between syntax and semantics is key
If we have so many existing ways for machines to communicate, why do we need to keep inventing more? The answer lies not in syntax (how things are represented in an encoding), but in semantics (the meaning of a statement).
Typically, we can have two very different representations, for example, the “TOKEN-374878324” and “TOKEN-66524190”. They could be text strings, printed on an image, or written in the sky using smoke signals. In any given situation, they could also be defined to mean:
- Precisely the same things (e.g., “Emergency!”)
- Very different things (e.g., “It’s hot” and “Pancake”)
Languages can combine tokens, for example:
- (TOKEN-374878324 (TOKEN-66524190))
Any language that uses these tokens needs to define the meaning of these compositions. In this example, for example, “The Pancake is Hot”.
In a human natural language such as English, typically, tokens have a unique or near-unique meaning, though not always. In English, in particular, there are often Saxon and Latin root words for the same thing (“Bravery” and “Courage”, for example). Or meanings can be close to one another but different (“Drizzle” and “Rain”, both get you wet, but to different degrees).
One could also take a sentence in human language, map it to numeric tokens, and then back again into the same language or a different one. In the ideal case, the meaning will be unchanged. (We do this all the time in LLMs.)
The key point is that the syntax of a language is connected to, but distinct from, the semantics. In digital systems, what matters a great deal is:
- If the semantics are explicit or implicit.
- How implementations process syntax and interpret semantics in order to determine which actions to take.
Another important distinction to note is that when we examine a concrete representation of something, it is not the actual thing. For example, the printed phrase “Orange (fruit)” is not, itself, an Orange. This seems obvious, but it is easy to forget when spending all day staring at messages. The statement “The Map is not the Territory” is often used as a reminder of this distinction.
Blackadder Goes Forth gives a brilliant illustration of one of the few cases where the map is the territory:
This distinction may seem pedantic, but understanding is crucial if we want to build functioning AI-to-AI communication. Syntax is always visible on the screen, but the machinery for interpreting semantics is often hard to pin down.
REST and MCP: more alike than they seem
Let's start with some examples.
A REST API call to get hotel listings could look something like this:
- GET /hotels?city=Mumbai&check_in=2025-06-10&check_out=2025-06-12
- POST /reservations -> {"hotel_id": "H123", "customer_name": "Alice Example", "check_in": "2025-06-10", "check_out": "2025-06-12"}
An MCP interaction via an LLM would look something like this:
- User: “Find me a cheap hotel in Mumbai from June 10–12.”
- Search_hotels tool called with {"location": "Mumbai", "check_in": "2025-06-10", "check_out": "2025-06-12" }
- Return “I found 2 hotels matching your dates…”
In both examples, the messages serve the same purpose: requesting a list of hotels for a given set of dates, followed by booking the hotel.
People say MCP is semantically more flexible than REST. In practice, the flexibility mostly comes from the LLM, not the protocol. From the examples, we can see that this is really only minimally true:
- It is the LLM that is cleverly turning a human language query into JSON, retrieving the result, and then reconverting the result.
- The MCP protocol itself isn’t actually adding semantic flexibility per se.
The main difference is that we’ve moved away from using the HTTP Verbs (GET, POST, PUT, etc.), each of which has its own specific meaning. We’ve also moved away from HTTP's assumption that every interaction is about a “resource” of some kind.
In this sense, MCP is more flexible, but this is a marginal difference, since HTTP semantics constrain only the flow of client-server interactions, not the content.
The flexibility here comes from an LLM that can process English and make the appropriate tool calls. MCP does have other advantages over REST APIs for certain interactions (e.g., Statefulness of the connection); however, it does not add anything significant in terms of Syntax or Semantics.
FIPA-ACL had semantic definitions baked in
FIPA-ACL tried to solve semantics directly by having full semantic definitions for every part of a message. Here is the same message encoded in FIPA's FIPA-ACL standard:
- (request :sender (agent-identifier :name A) :receiver (set (agent-identifier :name B)) :content "((action (agent-identifier :name B) (book H123 (c_in 2025-06-10) (c_out 2025-06-12)))" :protocol fipa-request :ontology hotel_booking :language fipa-sl :reply-with booking567)
This looks a lot more complex, but some indentation helps:

Here, the message uses a performative (also known as a speech act) REQUEST, that refers to an action to be taken, the agent or agents to take that action, references and ontology (containing key relevant context), and a protocol (a sequence of speech acts). The message also has a content body written in a logic-based Agent language (in this case, FIPA-SL).
What distinguishes the JSON specifications found in a REST API or an MCP call is that all elements of the message have formally defined semantics. Most importantly:
- “Request” (and all the other available message types) have a precise logical definition of their meaning.
- The meaning of all the elements in the content message is also well-defined.
There is a large collection of speech acts in FIPA-ACL; some look straightforward, some esoteric:
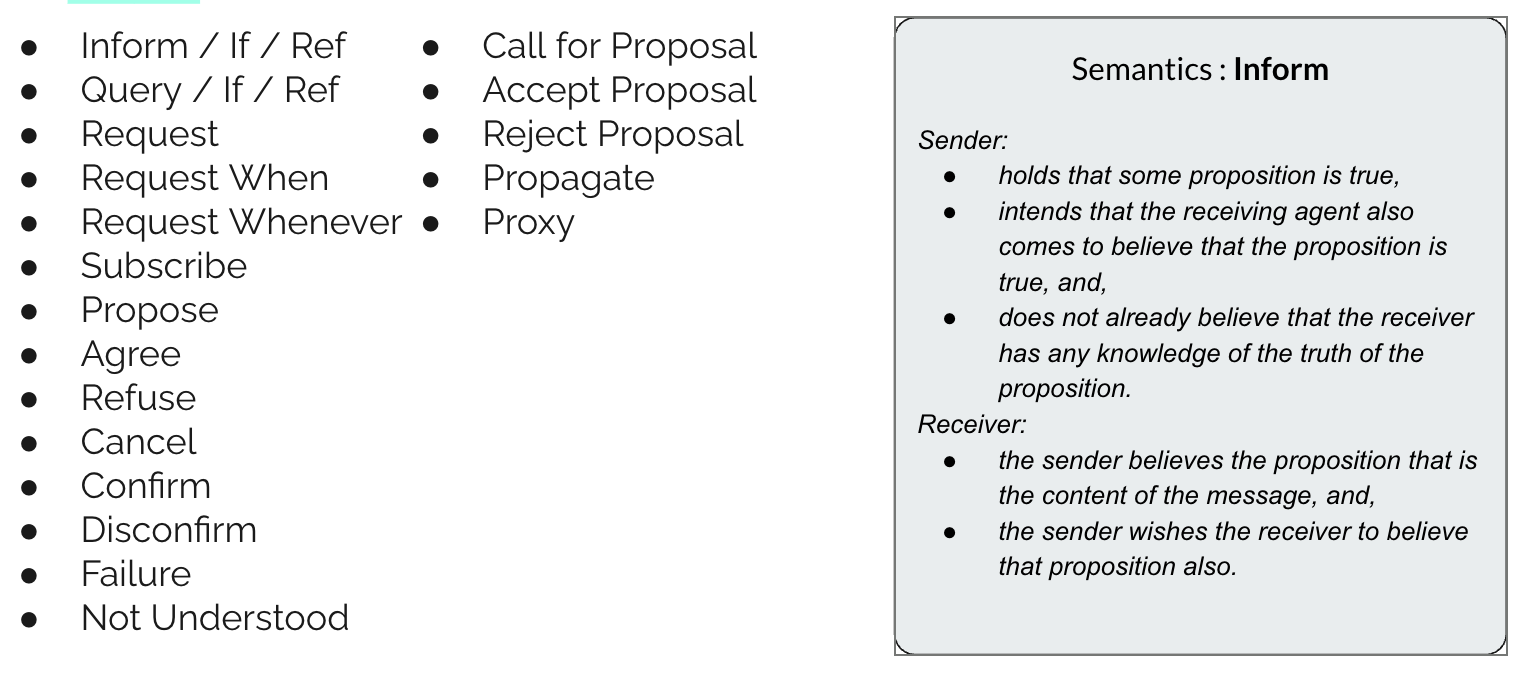
In the image above, we can see a list of message types available in the FIPA specification, along with one of the semantic definitions. (There are also logical symbol definitions.)
This semantic definition defines precisely what the intent of the sender is to communicate and what the receiver of the message is entitled to believe. Note that it is not forced to believe the content of the message; the receiver may believe the sender is lying. All this means is that the sender is expressing a particular intent.
As of a week ago, the original FIPA.org website seems to be offline. I've been reaching out to people to find out what happened, but all the formal specifications are linked at the end of this post.
The key benefit of using explicitly defined semantics for content is that:
Whereas for a REST API or MCP, one would have to hard-code the semantics of all possible messages into the server side (and for REST, the client as well), for FIPA-ACL, one can instead implement a general logic-based reasoning engine that implements the semantic rules only.
Then, when presented with any compliant message, the endpoint would be able to understand the meaning.
A2A highlights the peer nature of communications
A2A treats agents as peers, not tools.
The A2A protocol is technically very similar to MCP but has a different emphasis. The objective is to facilitate peer-level interaction between two intelligence systems (Agents). This differs from a client-server calling paradigm that assumes a single initiator and a single responder.
While A2A is currently less well established than MCP, but points to an important coming evolution: tool calling is important, but the real unlock is when peer systems communicate across networks.
To enable this peer communication, it is essential to have constructs such as identity, directory services, service descriptions, and so on. The core assumption that each communicating system is “opaque” and we can’t assume anything about its implementation is already present in MCP (and in REST APIS), but what becomes more important in A2A is that there is no longer an assumption of co-operation between Agents in the communication.
Agents may respond to messages, but they may well act in ways that are totally different from what one expects. The A2A protocol doesn’t explicitly state this as a goal, but it is the ultimate outcome of true “peer” communication.
In this regard, A2A is a lot closer in spirit to the FIPA and KQML agent language work from the late 90s and early 2000s.
The big challenge with A2A is that all the examples seem to suggest the use of English (or natural) language in messages between systems. While this is now in principle possible because LLMs could generate and interpret these strings, it makes strong assumptions about the power of the system on each end of the communication. Communication becomes extremely expensive if a powerful LLM is needed on either end for every message. A2A does not require natural language to be used, but the documentation seems to lean strongly that way.
Messaging needs (non-messaging) infrastructure to work
Communication only works if identity, discovery, and trust exist around it.
While I won’t go into this too much in this post, the FIPA standards effort started off by focusing on language. It quickly became clear, however, that you needed a whole range of defined systems that support the communications context:
- Naming, identity, and addressing
- Directory services
- Ontology services
- Multiple message encodings
- Multiple types of message transports
- Structured protocols (sequences of messages) or patterns, such as bidding or voting
- Institutions that set the context for trust or the enforcement of certain behaviours (e.g., public records of statements made by certain agents).
And much else. Protocols alone are not enough. We’re starting to see some of these needs reappear in protocols (e.g., A2A with the Agent card). I suspect we’ll see the whole range soon enough.
ChatGPT 5 Speaks FIPA-ACL
To close the stage presentation in London, I thought I’d have some fun and see if the new world understands the old.
To test this, I asked ChatGPT 5 to read the FIPA-ACL specification and respond to a series of messages using correct syntax and semantics. The results are surprisingly good. Here is the original prompt:

And the first message exchange. This isn’t quite correct, but it’s extremely close.
My second attempt originally looked like a failure, with ChatGPT responding negatively to my booking request from the example earlier in the article:

However, on closer inspection, ChatGPT gets this right for the following reason. I had indeed named the wrong agent as the actor in the example above. On correcting that, we get the right answer from ChatGPT:

The messages are similar to examples in the FIPA documentation. That plays to an LLM’s strengths. It would likely not do as well with entirely novel or complex nested logical statements, but it is still impressive as a first shot. One could also add a few-shot list of examples to improve performance.
Ultimately, an LLM isn’t really the right reasoning approach to handle logical languages such as FIPA-ACL and FIPA-SL. It would be hard to be sure it would be reliable. A good approach would be to provide the LLM with a sound logical reasoning engine as a tool (via MCP!) to check its working.
A team at MIT recently fine-tuned an LLM to works well on strategic planning using the logical language PDDL, and the results are encouraging. It is likely to me, though, that if you want sound and complete reasoning, the best combination today would be an LLM using a reasoner.
Conclusions and practical lessons
MCP, A2A, and other new protocols will evolve rapidly in the next few years, but many of the lessons from 20 and 30 years ago will still apply.
It is interesting to see the contrast and similarities between the standards work done 25 years ago and what is happening now. Many of the concepts and objectives transfer (and I believe are still relevant). The main thing we did not have in the early 2000s was a functioning all-purpose reasoner (all the logic-based reasoners had limitations), and certainly no non-symbolic processing engines like modern LLMs.
Neither did we imagine that these reasoners could effectively operate (even if not perfectly) on human natural language. While LLMs do not “understand” the semantics of (e.g., English) in the normal sense, they are generally able to select actions that align with intended meaning. This is extremely powerful.
So did we entirely waste our time 25 years ago? I don’t think so. You always have to work with the tools you have in front of you, and we built functioning systems ahead of their time. I also think using well-defined symbolic communication schemes is a powerful and important approach that will find its way back into AI-AI communication. Whether it is as a halfway house between hard-wired JSON schemas and fully flexible human language, or in languages that AIs themselves evolve for communications when there are no humans in the loop.
In the meantime, if you are building agent communication today, here is what to actually do:
- Make explicit decisions on where and how the semantic processing is being implemented. Is it being hardwired in a piece of application code? Is it a flexible bit of logic that processes set inputs? Is it a symbolic reasoner? Or an LLM-based AI system?
- Consider cost: what level of traffic volume do you expect in the communication channel? The higher the traffic volume, the less on-the-fly reasoning you want.
- How costly would errors be? If the error rate needs to be zero (in payment processing, for example), it makes no sense to do inline processing with today’s LLM-based technology.
- How flexible does processing need to be? If the incoming messages can be highly varied and lead to a wide range of system actions, then it’s best to move from hardwired APIs to more complex processing and plan for higher cost and error rates.
- Remember that at scale, communication goes well beyond the message but requires a myriad of other systems to work well: discovery, identity, encodings, message transports, security, authentication, and others. We’ll need AI-AI communications that operate well in a variety of contexts with different requirements in this regard.
Finally, we’ll end on a prediction. Given the tradeoffs just outlined, systems seem likely to converge to communication patterns that:
- ... are hardwired and tightly defined for most use cases of any volume,
- ... but these are built and maintained by flexible AI systems that define specifications and adjust them as communication needs evolve.
This provides the best of both worlds: reactive, fast, low-error communication when everything is standard, and the processing of exceptions and changes in a flexible way. This is the communication mirror of the cognitive System 1 / System 2 model often posited for intelligent systems.
Wrapping up with a dedication to Fabio Bellifemine
If you’ve read this far, then you’ve hopefully enjoyed a deep dive into the coming together of an old world (Agent communication languages and standards, the FIPA standard in particular) and a new world (MCP, A2A, and this new generation of powerful non-symbolic reasoners).
Someone who I’m sure would have been astonished by progress in recent years is Fabio Bellifemine, formerly of Telecom Italia Labs in Milan.

Fabio sadly passed away too early a number of years ago. He was a tireless advocate of standards; he pushed for correctness and kept many of us working on FIPA standards to higher and higher levels. He was also deeply involved in one of the leading implementations of the FIPA standard (the JADE platform). He was funny, kind, and stubborn in the best kind of way.. I think he would have been amazed and excited by what is possible today.
RIP Fabio, and thank you for the amazing dedication.
Where to find FIPA Standards
Until recently, the full FIPA standards archive lived at FIPA.org. Unfortunately, the site now appears to be offline. There is extensive work in these documents, so it would be a shame if they were lost. I've reached out to a few people to see if the site can be restored.
Luckily, a few weeks ago, I grabbed the gzip bundle of files, which contains all the standards documents in HTML and PDF format.
For now, they are available on Google Drive under FIPA.org Standards Documents. Hopefully, they will be back in place online soon.
UPDATE: Simon Thompson also made a mirror on Github.
About SteampunkAI
I write a weekly newsletter with the most interesting AI stories I come across that week, and occasionally add a long post like this one. If you’re interested in following along, you can sign up here: https://steampunkai.com