LLMs in the Architecture of a Mind
Sparks of unfiltered creation

LLMs are Ideation in the Architecture of a Mind
LLMs (Large Language Models) have taken the world by storm. From mid-journey to chatGPT, the outputs of the latest systems are hard to fathom. Often extremely impressive, human-like, and creative, yet sometimes maddeningly inaccurate. This makes it natural for users to think of these systems as smart, semi-conscious entities. The idea that an LLM could be considered an “intern” is quite prevalent.
For a number of reasons, though, this analogy doesn’t really hold. It’s not the LLM that’s the intern; it’s the system built around it. It’s much better to think of an LLM as the spark of creativity that animates the system rather than as the system itself.

That might sound like a stretch since many people argue that LLMs (or any type of machine) can’t be genuinely creative, but from an architecture of the mind point of view, it’s hard to see LLMs as much else.
Let’s get started with the easy part: how LLMs actually work.
How LLMs Work
When using Midjourney, ChatGPT, or one of the other systems, it’s easy to feel as though you’re conversing with an entity of some kind. You ask a question, and an answer pops out.
However, most people who have dug a little know that no “entity” is being conversed with. Instead, at their core:
LLMs are really “prediction machines” designed to predict the next token (word, pixel, or something else) in a sequence. These predictions are then chained together to produce whole sentences, images, videos and other outputs.
This means the response to a prompt such as “Describe the architecture of Le Corbusier” is not an answer based on a set of facts about Le Corbusier but a response that is the best fit for a response to this type of question. In other words, it’s a good guess at something that could pass for an answer. Often, this will use correct facts, but sometimes it will not since it may be confused by other architectural terms or references that sound like they may fit but don’t.

A more extreme example would be asking an LLM, “Will it rain in New York today?”. The out-of-the-box response would not be based on a weather report but instead on the best fit for a response to this type of question. In other words, it might say “Yes, it’ll rain in New York today” or “No, it won’t”, depending on how common similar phrases appeared in the training set.
In practice, LLM providers route around the more obvious versions of this problem by hardwiring in data sources for these types of queries. Google Bard’s response on rain is:

Sure enough, it looks like New York is in for thunderstorms:

For large LLM services, it’s important to realize that there are many cases where LLM responses are being augmented in this way so they don’t break in obvious ways. However, only so much can be done, and these patches are brittle. LLMs handle huge numbers of queries, and most will be handled by the LLM itself, not one of the overlay systems. In those cases, it’s important to realize what’s happening: the LLM follows a thread of best-fit answers until it finds something plausible.
There are already multiple great explanations of how LLMs work, and Stephen Wolfram gives one of the best detailed explanations. Understanding AI has a less insanely detailed version here :-).
A level of operation deeper
When processing a query, an LLM takes the prompt and generates one new token at a time. Each new token is then iteratively added to the set of inputs and submitted to the LLM again, adding more tokens until no more seem necessary. At that point, the system returns the response.

The Neural Network itself really sits at the center of a control loop in a system. In practice, there are further control loops around even this system that manage prompts and responses in all sorts of ways:
- Screening prompts for inappropriate terms
- Taking certain terms and adding special tokens to trigger the LLM in certain ways (for example, tokens associated with specific concepts that have been trained into the LLM using fine-tuning)
- Adding content from plugins or API calls into the prompt or the response to augment the process
- Screening responses to see if they contain objectionable material.
These manipulations and more form a part of an outer control loop around the LLM. In some cases, secondary LLMs are even used for some of these filtering processes.
This picture already makes it easy to see that the LLM is a component in a larger system.
Analogies in Architectures of the Mind
Cognitive Science and Artificial Intelligence researchers have posited many models of how minds could function. These range from biological analyses as to what different parts of a human or animal brain appear to do to highly abstract theoretical models that describe logical steps in a cognition process. Amongst the simplest abstract definition of an intelligent system is the sense-act loop (loosely defined in [MacCarthy58]):
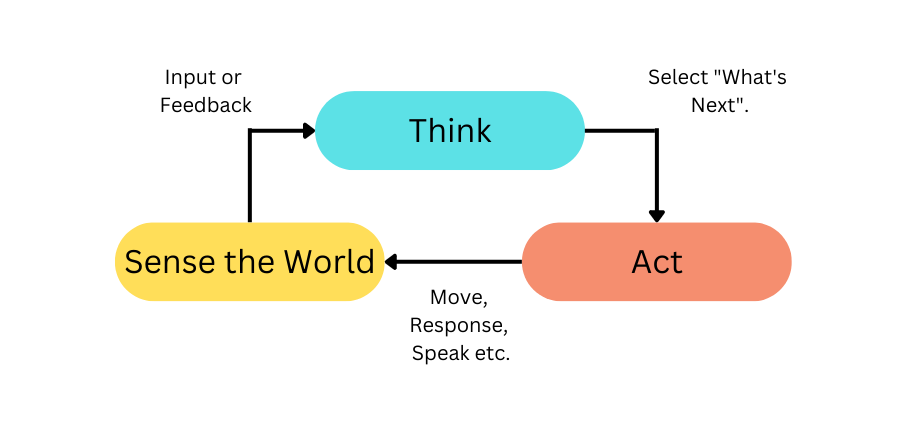
Going further, there are many ways to unpack the “think” box in this diagram. The simplified LLM Architecture in the previous diagram is one. A more general architecture would look like this:

This architecture tries to take a “symbolic” or “explicit” approach to describing what is in the “think” component of a system. Some of the standard components you’d see in such a description would be:
- A world model that approximates the real world and could be used to simulate what changes in the world an action might result in.
- A set of goals the system has. For a robot, this might be navigating to the end of a hall; for a game-playing AI, it might be to maximize the score.
- An ideation component that can suggest potential actions to take “next” to change the world. This could be as simple as a list of options to try or as complex as a full neural network.
- An evaluation component that scores which of the possible actions have positive outcomes with respect to the world and the current goals.
- A decision component that selects between the possible options of actions to take and executes one of them.
The perception and action elements of the system could be text queries and text responses (for chatbot), game world information and control commands in a video game, or robotic sensors and actuators (on a robot).
But.. “Wait a minute,” I hear you shout, “doesn’t this architecture conflict with the one in Diagram 1? LLMs don’t actually have a world model or a set of goals, right? So what’s going on.”
This hits the primary behind the post. LLMs don’t explicitly have these components, but to function at all, they arguably have them implicitly. These components are baked into the Neural Network itself as a result of the training process or added as a wrapper when queries are processed. The fact that these components are implicit (or “emergent”) is also the reason why LLMs perform poorly for certain types of query.
The goals of an LLM are easy to see. The LLM is trained to find the best fit for the next token in the sequence, and the LLM system is designed to return the most probable best-fit response. Hence, the goal is “following on in a way which would be considered a good fit.” In practice, there are also other goals that LLM system builders add, such as not responding with curse words or incorrect information about today’s weather. These goals (and compliance with them) are essentially hard-wired into the LLM system above and beyond how the Neural Network responds.
The world model component is much harder to see. LLMs give poor answers to many seemingly easy questions requiring some modeling of the world. In an example here, Bard is given three points in space and asked about the inferred altitude of the third point.

This seems quite hard, but given the distances, C must be between A and B on a straight line. Some simple trig would solve this. With more prompting, it becomes clear that Google Bard has two problems: it assumes C must be further higher than C for some reason and that terrain might need to be navigated in between. Even clarifying this, however, it didn’t get to the answer. Such a mathematical example could probably be captured. However, it illustrates the problem that LLM doesn’t have an underlying model to work with. The lack of causal reasoning (see this paper on causal reasoning in LLMs and this one on Reasoning / Interpretation) can be disconcerting, but it’s because the LLM does not construct a hypothesis of the world and then try to see what might happen if certain actions were taken. However, for many problems, LLMs are surprisingly good:

Here, ChatGPT can correctly identify that deckchairs on the Titanic that were not nailed down might have been swept off by a wave. This looks eerily like knowledge of the physical world. How is this possible without a world model? ChatGPT has a fuzzy world model of possible causal relationships implicitly encoded within it to give such answers. The constant looping of what “sounds” right resonates enough with combined training examples that some causal patterns appear in answers. This is one of the wonders of the current LLM state of the art; although the implicit model is weak, it is good enough for many simple world examples. Some researchers are now trying to explicitly teach LLMs world models, which could lead to exciting results. Integrating LLMs with symbolic computation engines such as Wolfram Alpha will likely lead to interesting progress.
The evaluate component is part implicit and part explicit in the current LLM system. Implicitly, the LLM core loop picks a learned best-fit response to a query. As such, each step applies an evaluation function to determine what should be next that is “good”. The explicit element comes in the post-filtering many LLMs do. This is an explicit check that answers do not violate some ethical or legal standards put in place by the vendor. In certain systems, it may also be choosing between various possible outputs.


The final blue box in the diagram is Ideation: the system for generating possible actions to take.
LLMs as Ideation
In current LLM systems, the Neural Network acts as an ideation engine, spitting out each new next token as it goes, and the wrapped we saw in diagram 1 composes this into a full response. As we saw in the previous section, the architecture of these systems means that functions such as the world model, goals, and evaluation are implicit and baked into the LLM itself.
While this works, it’s likely a much better model to think of LLMs as primarily “ideation” in the architecture and not the whole system:
- To get really good at many tasks, they’ll need to access custom world models for specific purposes and tasks - some of which will be domain-specific.
- To be generally useful, it will likely be necessary to have fine-grained control of the goals of these systems. These would range from high-level goals such as “don’t harm anyone” to specific ones, “don’t violate the code of ethics with any suggested actions.”
- Evaluation will also likely need to go deeper than what the ideation LLM itself is capable of by taking suggested courses of action and simulating their possible impacts.
Today’s LLM system already provides a thin layer of this, but, unsurprisingly, results are spotty if we’re really being exposed to almost pure ideation.
It also makes it obvious why the best use cases of LLMs today are in creative applications where a human expert is in the loop: creation, art, or writing computer code. In both cases, the ideation engine quickly creates plausible outputs, but a human operator sets goals fine-grained and acts as the evaluation function.
To make LLMs truly useful (especially if fully autonomous), the trick will be to replace these human factors effectively enough for the system to work. This will likely only be possible in narrow domains, to begin with.
LLMs are already evolving
This will be an exciting area for a long time, but we can already see LLM architectures evolving:
- There are already rumors that GPT4 is not one large Neural Network model, but a mixture of eight smaller integrated models. Each model is a separate trained model with a slightly different potential specialty.
- Meta’s new I-JEPA is trained on abstract concepts derived from data rather than just the raw training data.
- Microsoft’s Bing packaging of ChatGPT now includes a memory element that retains information about previous chats. Taken to an extreme, this might be the basis of having a short-term capture or state for a world model. They look to be going even further with LLM-AUGMENTER.
The last word - but is it really creative?
Hopefully, I’ve persuaded you by this point that the best way to think of today’s LLM systems is as wild idea generators. Generators that will require a lot of harnessing to work in contexts beyond those in which human experts can guide them.
There may still be a wrinkle in the argument: the question of “but can LLMs ever really be creative?”. I’ll leave this one for a future in-depth post, but suffice it to say that I think, for all intents and purposes, LLMs are plenty creative.
A poster on this Hacknews thread puts it perfectly:
I think that better philosophers than us debated this question for thousands or years but I'll give my take. Suppose that creativity means to find a particular place in the n-dimensional space of all possible ideas. Artists find some interesting places in that space in part because they started from other interesting places nearby. They know those nearby places and we don't, because we trained to do a different job. However we have our share of creativity.
Algorithms like GPT or Stable Diffusion explore that n-dimensional space starting from possibly more places than a single human has experienced. They will miss many of the starting points that any human experiences, because of limits of those algorithms' interfaces with the world. However they can still find interesting places. Maybe it's not creativity as we mean it, but they can show us interesting places that no artist has found before.
In other words, at some basic level, creativity is about exploring the space of all answers to a question. Any given human will explore that space in a particular way. A group of humans might explore it in a wholly different way. AI does it differently again.
Luckily, in many cases, generating a solution somewhere in the space has a cost, but evaluating whether it is good or bad can be very quick. All it takes is one cool AI-generated output that you would not have thought of, and suddenly, your imagination runs on a completely different rail.
A long first post
This substack will be about a much broader swath of AI than LLMs (Large Language Models), but we'll start there since this has driven such a change in AI over the past 12 months.
The first post did get long, but it seemed like a useful bit of context for future things - many of which will be a lot shorter!
I’ll aim for one post per week; let’s see how that goes! Subscribe if you’d like to join for the ride!
Notes:
- Images created using Midjourney AI.
- Diagrams by hand.
References:
- [MacCarthy58] John McCarthy in his 1958 paper, "Programs with Common Sense." (This is one of the papers that started AI Research as a whole, in particular knowledge representation: /content/files/selman/cs672/readings/mccarthy-upd.pdf)
- (https://openreview.net/forum?id=tv46tCzs83)